

Как правильно выбрать сервер: гайд от Bquadro для заказчиков сайтов
Когда в Bquadro приходит новый клиент с запросом «нужен сайт», почти всегда за этим стоит второй, не проговоренный вслух вопрос: «а где всё это будет крутиться и что мне для этого купить?». В этой статье мы расскажем, как мы вместе с заказчиками разбираемся в терминах, переводим бизнес-требования в цифры нагрузки и выбираем тип сервера — от shared до VDS, bare metal и облака.
Что такое сервер и зачем он нужен
Сервер — это специализированный компьютер или программно-аппаратный комплекс, предназначенный для хранения данных, обработки запросов и предоставления ресурсов и сервисов другим устройствам (клиентам) по сети в круглосуточном режиме.
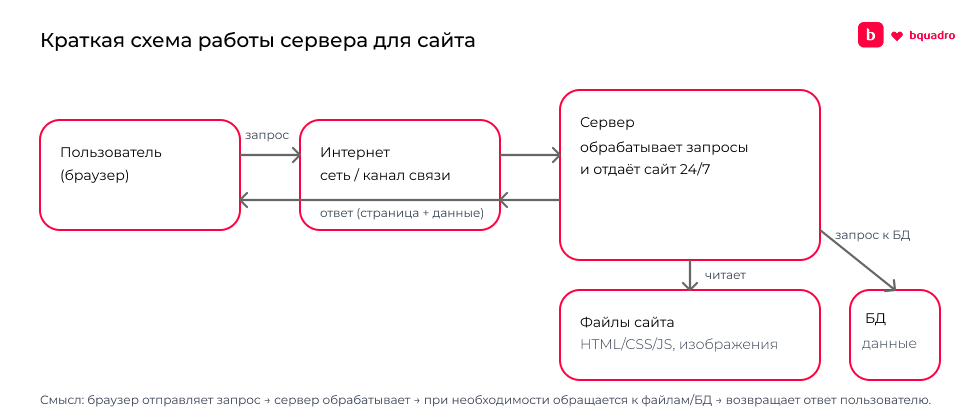
Сервер — это основа работы любого сайта. Если упростить, сервер — это компьютер, который круглосуточно хранит файлы сайта, обрабатывает запросы пользователей и «отдаёт» страницы посетителям, когда они открывают сайт в браузере. Именно сервер отвечает за то, чтобы сайт открывался быстро, стабильно и был доступен 24/7 из любой точки мира.
Когда пользователь заходит на сайт, его браузер отправляет запрос на сервер. Сервер обрабатывает этот запрос, получает нужные данные (тексты, изображения, товары, личный кабинет, корзину и т. д.) и возвращает результат пользователю. Чем надёжнее и производительнее сервер, тем быстрее работает сайт и тем меньше риск сбоев, ошибок и недоступности.
Выбор сервера напрямую влияет на скорость загрузки страниц, безопасность данных, устойчивость сайта к нагрузкам и возможность его дальнейшего роста.
Старт: заказчик, сайт и туман терминов
Первое, что необходимо сделать перед выбором конкретной технологии, — это понять, для чего нужен сервер, какая будет нагрузка.
Типичный сценарий: к нам приходит компания с задачей запустить интернет-магазин или портал на CMS Bitrix. Есть маркетинговый план, бюджеты на рекламу, но инфраструктура описана фразой «обычный хостинг, как у всех». На звонке часто звучат фразы:
-
«Нам сказали, что хватит обычного VPS».
-
«Чем VDS отличается от VPS, и почему одни провайдеры пишут одно, другие другое?»
-
«Нам нужен сервер, чтобы „держал“ рекламу и интеграцию с 1С».
Мы начинаем не с выбора тарифа, а с вопросов:
-
Сколько одновременных пользователей вы ожидаете в пике? (пример: 300–500 человек во время распродажи).
-
Какую долю продаж вы готовы потерять, если сайт будет открываться 3–4 секунды вместо 1–2?
-
Есть ли регулярные тяжёлые операции: выгрузки из 1С, генерация отчётов, импорт каталогов?
-
В каких регионах живут пользователи: одна страна или сразу несколько часовых поясов?
Ответы позволяют перевести «хочу, чтобы работало быстро» в понятные для инженеров параметры: запросы в секунду (RPS), объём данных, профиль нагрузки по часу/дню.
Основные виды серверов
Дальше мы достаём условную «карту инфраструктуры», рассказываем заказчику, какие бывают сервера, и проговариваем основные типы размещения:
-
Shared-хостинг — много сайтов на одном сервере, ресурсы делятся. Минимальная цена, минимальный контроль и непредсказуемое поведение под нагрузкой.
-
VPS (Virtual Private Server) — виртуальный сервер с гарантированной долей ресурсов, но соседние клиенты всё ещё могут влиять на производительность.
-
VDS (Virtual Dedicated Server) — виртуальный выделенный сервер: фиксированные ядра CPU и RAM, поведение ближе к выделенному железу.
-
Bare metal — физический сервер целиком ваш: максимум контроля, но и максимум ответственности.
-
Cloud (облако) — набор виртуальных машин и управляемых сервисов, которые можно масштабировать через API.
-
Serverless/FaaS — вычисления «по событию», без управления серверами, обычно как дополнение, а не основа сайта.
Мы показываем, как каждый вариант влияет на пользовательский опыт (скорость загрузки, стабильность в пике) и операционную сторону (кто отвечает за обновления, бэкапы, мониторинг). В этот момент мы аккуратно погружаем заказчика в технические детали, но связываем каждую цифру с бизнес-риском: «если нет NVMe-диска, каталог товаров с фильтрами будет открываться дольше, и часть пользователей уйдёт».
Типы серверов: сравнительная таблица
|
Тип |
Ресурсы и контроль |
Плюсы |
Минусы |
Типичный кейс |
|---|---|---|---|---|
|
Shared |
Общие CPU/RAM/диск с другими клиентами |
Минимальная цена, быстрый старт |
Непредсказуемая нагрузка, мало настроек |
Лендинг, небольшой сайт |
|
VPS |
Виртуальная машина, доля ресурсов |
Root‑доступ, гибкая конфигурация |
Соседи всё ещё могут влиять на производительность |
Bitrix с умеренной нагрузкой |
|
VDS |
Виртуально выделенные ядра и RAM |
Предсказуемая производительность, VLAN |
Дороже VPS, нужен DevOps/админ |
Крупный Bitrix‑портал/магазин |
|
Bare metal |
Физический сервер целиком под проект |
Максимальный контроль и производительность |
Высокая цена владения, сложность эксплуатации |
Высоконагруженные и критичные системы |
|
Cloud/IaaS |
Набор VM и сервисов по API |
Масштабирование, быстрые эксперименты |
Сложность конфигурации и безопасности |
Много сервисов, распределённая архитектура |
Как выбрать сервер под ваши нужды: чек-лист
Когда мы подходим к выбору конкретного варианта, мы вместе с заказчиком проходим короткий чек-лист:
-
Размер и сложность проекта
-
До 10 страниц, без интеграций → shared.
-
Bitrix с каталогом и 1С, но без жёстких SLA → VPS.
-
Крупный Bitrix‑портал/магазин с личным кабинетом и отчётами → VDS.
-
Критичная система с жёсткими требованиями по доступности и производительности → VDS + bare metal.
-
-
Нагрузка и рост
-
Пиков мало и они прогнозируемы → достаточно VPS с запасом по ресурсам.
-
Постоянные пики, регулярные акции, множество интеграций → вынос БД и тяжёлых задач на отдельные VDS/серверы.
-
-
Требования к отказоустойчивости
-
Допустимы редкие короткие простои → один сервер и регулярные бэкапы.
-
Нужен минимальный downtime → несколько узлов, репликация БД, отработанные сценарии восстановления.
-
-
Команда эксплуатации
-
Нет своего админа, минимум техподдержки → простые схемы (shared/VPS) с управляемыми сервисами.
-
Есть свой DevOps или аутсорс‑команда → можно использовать VDS/bare metal и гибридные схемы.
-
-
Бюджет и горизонты развития
-
Важно стартовать дёшево и быстро → минимальный вариант с понятным планом миграции.
-
Важнее сразу заложить запас на рост → VDS/комбинация VDS + bare metal, продуманная схема по виртуалкам и бэкапам.
-
Ответы на эти вопросы позволяют заказчику понять, как выбрать сервер, а также совместно определить стартовую точку и прописать «следующий шаг» по мере роста проекта, чтобы решение по серверу всегда опиралось на метрики и бизнес‑цели, а не только на интуицию.
VDS против VPS: что лучше
Отдельный блок — разбор VDS и VPS. Чаще всего клиент приходит с фразой: «нам рекомендовали VDS, говорят, это почти как выделенный сервер». Мы объясняем на примере:
-
У VPS есть пул ресурсов, который провайдер может слегка «перепродавать» между клиентами. При всплеске у соседей ваш CPU может кратковременно «просесть».
-
У VDS набор ядер и объём RAM зарезервирован только за вами. Это особенно важно для Bitrix и других тяжёлых CMS, которые активно используют базу данных и файловую систему.
Дальше мы достаём реальные спецификации Timeweb, Reg.ru, Sweb и показываем на цифрах:
-
Timeweb VPS Ultra — 4 vCPU на базе Intel Xeon, NVMe 80 ГБ, канал 1 Гбит/с, DDoS Shield.
-
Reg.ru VDS/Bare Metal — до 8–16 физических ядер (Zen 4 / Xeon), NVMe в RAID, 10 Gbps uplink, management VLAN и IPMI.
-
Sweb Cloud — профили от 2 до 16 vCPU с Turbo Boost, NVMe на каждом узле и полосой 1–5 Gbps, со встроенным балансировщиком трафика.
Для заказчика это превращается в понятную картинку: VPS — разумный старт, VDS/bare metal — когда важна предсказуемость и высокий SLA, cloud — когда нужно быстро масштабироваться и выходить в новые регионы.
Как мы переводим бизнес-требования в технические метрики
На этом этапе мы делаем то, что редко делают классические «хостинг-менеджеры»: вместе с заказчиком собираем реальные цифры.
Смотрим, сколько PHP-процессов, воркеров очередей и фоновых задач планируется. Переводим это в ядра и RAM. Если Bitrix, учитываем агенты, CRON и интеграцию с 1С.
Объясняем, что NVMe может давать десятки тысяч операций ввода-вывода в секунду, тогда как SATA SSD — в разы меньше. Для интернет-магазина с фильтрами и поиском это критично.
Разбираем, почему канал «до 100 Мбит/с» на shared-хостинге не равен гарантированному 1 Гбит/с на VDS, и как на скорость влияет близость дата-центров и стабильность каналов связи.
Просим маркетинговый план: если планируются акции, интеграции с маркетплейсами, push-кампании — закладываем запас по ресурсам (часто x2 от средней нагрузки).
Мы используем Prometheus и Grafana или встроенные панели провайдеров, чтобы не гадать. Даже если проект только запускается, можно взять статистику похожих ресурсов или провести нагрузочный тест.
Сетевые вопросы, о которых редко думают в начале
Когда клиент слышит «сервер», он часто представляет только CPU и память. Мы отдельным блоком объясняем сетевую часть:
-
VLAN и private subnet. Для проектов, где есть внутренняя администрация, CRM, база данных, мы отделяем внутренний контур в приватную сеть. Reg.ru и Sweb позволяют строить такие VLAN, Timeweb даёт private-сети для VPS.
-
Firewall и DDoS. Показываем разницу между простым «закрыты порты» и полноценной защитой: L3/L4-фильтрация, rate limiting, гео-правила. Многие российские провайдеры дают API для управления firewall, это важно для автоматизации. — Отдельные сервисы раздачи статики и оптимизация маршрутизации помогают сократить время загрузки картинок, видео и статических файлов для пользователей из разных регионов.
Здесь мы часто показываем упрощённый пример кода инфраструктуры как кода (IaC). Например, как можно зафиксировать правила firewall через Terraform, чтобы потом без боли переехать к другому провайдеру:
resource "reg_ru_firewall_rule" "web" {
direction = "inbound"
protocol = "tcp"
port_range = "80,443"
action = "accept"
source_ips = ["${var.office_ip}"]
}Даже если заказчик не пишет этот код сам, он понимает: сеть — это тоже часть продукта, а не «магия хостинга».
Расширение сетевого окружения: что можно сделать для каждого типа сервера
На следующем уровне погружения мы обсуждаем с заказчиком не только «где крутится сайт», но и «как вокруг него устроена сеть». Разные типы серверов дают разные уровни свободы: где‑то достаточно включить HTTP/2 и грамотно настроить кеширование, а где‑то мы проектируем полноценный многоуровневый периметр с приватными подсетями, VPN и балансировщиками.
Shared‑хостинг: минимум свободы, ставка на внешние сервисы
На shared‑тарифах сетевое окружение почти полностью контролирует провайдер. Что мы можем сделать:
-
включить HTTPS через панель, следить за корректной настройкой TLS;
-
убедиться, что на стороне хостинга включены актуальные версии PHP, опкеша и базовой защиты;
-
настроить регулярные бэкапы файлов и базы данных и протестировать процедуру восстановления из панели.
По безопасности здесь почти всё «на совести» хостинга и внешних сервисов: он отвечает за системный firewall, сегментацию клиентов и защиту самого железа. От команды проекта требуется только грамотная настройка DNS, HTTPS и базовых WAF‑правил в панели. Привлекать отдельного DevOps на этом уровне обычно избыточно, но важно понимать, что и глубоко защититься здесь невозможно — просто нечем управлять.
Пример влияния: для контентного сайта или лендинга это часто уже даёт ×2 улучшение скорости в регионах и защиту от простых DDoS/ботов. Но как только появляется интеграция с 1С или тяжёлый каталог, мы упираемся в то, что нельзя разделить внутреннюю и внешнюю сети, невозможно построить приватный контур для баз данных, да и нет доступа к системному firewall. В таких кейсах мы прямо говорим: shared — максимум старт, без перспектив серьёзной сетевой архитектуры.
VDS: когда сеть становится частью архитектуры
С VDS всё то же, что и с VPS, но в более предсказуемом исполнении: выделенные ядра и RAM позволяют жёстче планировать нагрузку, а провайдеры чаще предлагают полноценные private VLAN, отдельные интерфейсы и расширенные опции firewall.
Что мы делаем на уровне сети с VDS:
-
строим отдельный VLAN для контуров «веб‑сервер ↔ база данных ↔ сервисы очередей»;
-
разделяем внешние и внутренние IP: внешний принимает HTTP/HTTPS‑трафик, внутренний — только служебные запросы;
-
поднимаем отдельный bastion‑хост/VPN‑шлюз, через который администраторы попадают внутрь инфраструктуры;
-
включаем аппаратный/сетевой DDoS‑фильтр на стороне провайдера плюс дополнительные WAF‑правила;
-
используем несколько VDS в связке: один фронтовой (reverse proxy, WAF, кэш), один или несколько под Bitrix/приложение, отдельный под БД.
По безопасности это уже полноценная мини‑инфраструктура: провайдер даёт инструменты (VLAN, DDoS‑фильтр, отдельные интерфейсы), но архитектуру периметра, правила доступа, журналы событий и процессы реагирования строим мы вместе с клиентом. На этом уровне DevOps/сетевой инженер — не роскошь, а необходимость: без человека, который понимает, как связаны ACL, NAT, VPN и политики в WAF, легко получить либо дырявый периметр, либо чрезмерно закрытую систему, в которой страдает бизнес.
Конкретный кейс: крупный B2C‑магазин на Bitrix с интеграцией 1С и личным кабинетом. Мы проектируем схему из трёх VDS:
-
Front‑VDS — Nginx/HAProxy, TLS‑терминация, кэш, статические файлы, WAF (здесь нет отдельного «фронтенда» как сервиса, это скорее «щит» перед монолитным Bitrix).
-
App‑VDS — PHP‑FPM/Bitrix, очереди, cron, сервисы интеграций; здесь живёт и публичная часть, и админка, как это привычно для Bitrix.
-
DB‑VDS — MySQL/PostgreSQL, репликация, отдельный приватный диск под бэкапы.
Между ними — приватный VLAN, из внешнего мира виден только front‑сервер. Это повышает безопасность и позволяет независимо масштабировать оба слоя: при росте нагрузки можно увеличить ресурсы front‑VDS или добавить ещё один узел, не трогая базу.
Отдельный бонус виртуализации на уровне VDS — работа с бэкапами. Мы можем делать снапшоты каждой виртуалки: отдельно для базы, отдельно для приложения. Это позволяет, например, откатить только БД к консистентной точке, не трогая файловую часть Bitrix, или развернуть тестовое окружение, клонировав app‑VDS и DB‑VDS из ночных бэкапов. Восстановление из бэкапа превращается в операцию «поднять нужную виртуалку», а не «восстановить весь сервер целиком».
Bare metal: полный контроль и «железная» сеть
На bare metal к серверу часто прикручен набор сетевых фич: несколько физических интерфейсов, поддержка bonding/LACP, возможность подключать несколько VLAN, BGP‑анонсы, выделенные management‑порты (IPMI/BMC).
Что это даёт нашим клиентам:
-
возможность физически разделить нагрузку по интерфейсам: один — под публичный веб, второй — под репликацию баз и внутренние сервисы;
-
построить отказоустойчивый канал с двумя uplink‑ами (например, 2×10 Gbps) и использовать агрегацию каналов;
-
использовать собственные маршрутизаторы/апплайансы (например, аппаратные firewall или VPN‑шлюзы), если у клиента строгие требования по безопасности;
-
настраивать сложные схемы балансировки и геораспределения через BGP‑анонсы или GRE‑туннели между своими площадками.
Безопасность здесь практически полностью на стороне команды клиента и/или нашей команды: провайдер отвечает за физическую защиту, отказоустойчивость каналов и базовый DDoS, всё остальное — конфигурация и обновление firewall, IDS/IPS, VPN, контроль доступа к IPMI — требует компетентного DevOps/сетевого инженера. Мы всегда предупреждаем: bare metal без сильной команды эксплуатации — рискованный выбор, даже если сам сервер очень мощный.
Пример: крупный B2B‑портал с разделёнными зонами для клиентов, партнёров и внутреннего персонала. Мы помогаем ИТ‑отделу клиента поднять bare metal в дата‑центре провайдера, подключить его к их существующему MPLS‑ или VPN‑кольцу, развести подсистемы по VLAN («публичный портал», «личные кабинеты», «админка/внутренние сервисы»). В результате соблюдаются внутренние политики безопасности и отраслевые нормативы — при этом веб‑часть работает так же быстро, как в облаке.
Как сетевые настройки влияют на проект
Чтобы связать всё это с бизнес‑результатом, мы приводим несколько типичных сценариев:
-
Интернет‑магазин на единственном VPS. Растёт объём каталога и число одновременных посетителей, страницы открываются по 4–5 секунд из‑за высокой нагрузки на дисковую подсистему и базу. После перевода на NVMe, включения кеширования запросов Bitrix и оптимизации индексов БД время загрузки сокращается до 2–2,5 секунд, а конверсия в корзину растёт на несколько процентов.
-
Bitrix‑портал на VPS без приватной сети. Интеграция с 1С работает по публичному интернету, в логах — всплески ошибок при нестабильных каналах. После переноса на VDS с VPN‑туннелем и приватным VLAN количество ошибок резко падает, окна обмена сокращаются, а служба безопасности клиента закрывает риск по утечке данных.
-
SaaS‑сервис в облаке без сегментации. Все компоненты живут в одной подсети, инциденты безопасности сложно локализовать. После разделения на фронт‑, апп‑ и DB‑подсети, включения WAF и ограничений по IP для административных панелей риск компрометации снижается, а аудит проходит значительно легче.
Во всех этих примерах мы не просто «крутим галочки» в панелях провайдера. Мы показываем заказчику, как конкретная конфигурация серверов и баз данных (новый VLAN, вынос БД на отдельную виртуалку, настройка кешей, оптимизация индексов, VPN‑канал, WAF‑правило) уменьшает риск простоя, утечки или падения скорости, и как это связано с деньгами в его бизнесе.
Мониторинг и сигналы к переезду: как мы это объясняем клиентам
Мы честно говорим: выбор сервера — это не раз и навсегда. Проект растёт, нагрузка меняется, и важно понимать, по каким сигналам нужно «переезжать» или усиливать инфраструктуру.
Мы показываем заказчику набор базовых триггеров:
-
CPU стабильно выше 70% в течение 15–20 минут при обычной нагрузке.
-
Latency страниц превышает 300–400 мс, а пользователи жалуются на «медленный сайт».
-
Disk IO выходит за 2000–3000 IOPS для типичных операций.
-
Появляется packet loss выше 0,5% и рост TCP retransmits.
-
В логах участились ошибки 5xx в пиковые моменты.
Все эти метрики мы визуализируем в Grafana и настраиваем алерты. Для заказчика это превращается в простой сценарий: «если пришёл такой-то алерт — пора обсуждать масштабирование». Мы заранее проговариваем с клиентом, до какого порога можно жить на VPS, когда переходить на VDS, и какие шаги потребуются.
Кейсы по типам серверов: от лендинга до высоконагруженной системы
Чтобы связать всё сказанное с практикой, мы с заказчиком разбираем жизненные сценарии — от самого простого до максимально сложного.
Кейc 1. Лендос и небольшой сайт компании на shared‑хостинге
Небольшой сайт с 5–10 страницами, формой обратной связи и новостями. Никаких интеграций с 1С, посещаемость — несколько сотен визитов в день.
-
Тип сервера: shared‑хостинг.
-
Конфигурация: минимальный тариф, актуальная версия PHP, включённый opcache, база MySQL в общем пуле.
-
Настройки: включаем HTTPS, настраиваем регулярные бэкапы файлов и БД через панель, проверяем восстановление на тестовом поддомене.
-
Мониторинг: достаточно простых аптайм‑чеков и логов веб‑сервера.
Такой сценарий хорош, чтобы быстро запуститься с минимальными затратами. Как только появляется Bitrix или интеграции, мы сразу планируем переезд.
Кейc 2. Internet‑магазин на Bitrix с умеренной нагрузкой на VPS
Интернет‑магазин на Bitrix с каталогом до 10–20 тысяч товаров, интеграцией с 1С раз в несколько часов и регулярными маркетинговыми акциями.
-
Тип сервера: VPS.
-
Конфигурация: 4–8 vCPU, 8–16 ГБ RAM, SSD или NVMe, одна виртуалка с монолитным Bitrix (публичная часть + админка + БД на том же сервере или в managed‑БД у провайдера).
-
Настройки:
-
раздельные пулы PHP‑FPM для публичной части и админки;
-
включён opcache, кеширование в Bitrix (файловый/мемкеш/redis в зависимости от стека);
-
оптимизированные лимиты MySQL (innodb_buffer_pool_size, max_connections) под объём RAM;
-
cron‑задачи Bitrix и интеграций вынесены на ночные окна или распределены по времени.
-
-
Мониторинг: базовый Prometheus + node_exporter, графики CPU, RAM, disk IO, latency, количество 5xx.
Этот вариант подходит, пока нагрузка и объём интеграций умеренные. Порог — устойчивые пики CPU/RAM и рост времени ответа при импортах/акциях.
Кейc 3. Bitrix‑портал с выносом БД на отдельную VDS
Корпоративный портал или крупный интернет‑магазин на Bitrix с активным личным кабинетом, интеграциями с 1С и CRM, ежедневными отчётами и сложной фильтрацией каталога.
-
Тип сервера: несколько VDS.
-
Конфигурация:
-
App‑VDS: 6–8 vCPU, 16–32 ГБ RAM, NVMe под код и кеши, Bitrix (публичная часть + админка).
-
DB‑VDS: 4–8 vCPU, 32–64 ГБ RAM, NVMe/RAID под MySQL/PostgreSQL, отдельный диск под бэкапы.
-
-
Настройки:
-
приватный VLAN между App‑VDS и DB‑VDS, доступ к БД только по внутреннему адресу;
-
тщательно настроенный innodb_buffer_pool, индексы под основные выборки Bitrix;
-
включён query‑cache/кеш запросов Bitrix, разделение БД на рабочую и архивную при необходимости;
-
вынесенные очереди и тяжёлые задания (импорт, генерация отчётов) в отдельные worker‑процессы с лимитами по ресурсам.
-
-
Мониторинг: отдельные дашборды для приложения и базы, алерты по CPU, IOPS, росту времени выполнения запросов, количеству блокировок.
Здесь мы уже чётко разделяем ресурсы: если «горит» база, увеличиваем ресурсы DB‑VDS или оптимизируем запросы, не трогая app‑слой.
Кейc 4. Высоконагруженная система на Bitrix с множеством интеграций и глубоким мониторингом
Крупный e‑commerce/портал услуг на Bitrix, который выдерживает десятки тысяч пользователей в день, интегрируется с несколькими внешними системами (1С, ERP, платёжные шлюзы, маркетплейсы), имеет сложную логику скидок и отчётности.
-
Тип сервера: VDS + bare metal (или группа мощных VDS).
-
Конфигурация:
-
Front‑узел: VDS с Nginx/HAProxy, TLS, кешем и rate limiting.
-
App‑узлы: несколько VDS с Bitrix, разделение по ролям (публичные запросы, админка, API).
-
DB‑узлы: один или несколько серверов (VDS/bare metal) с репликацией, отдельными дисками под журнал и данные.
-
Отдельные виртуалки под интеграции и фоновые сервисы (очереди, отчёты, генерация выгрузок).
-
-
Настройки:
-
горизонтальное масштабирование Bitrix по схеме «несколько app‑серверов + общая база»;
-
строгая дисциплина индексов и периодическая архивация данных;
-
разделение read/write‑нагрузки по репликам БД (если это оправдано бизнес‑логикой);
-
глубокая настройка PHP (opcache, JIT при необходимости), тщательно подобранные лимиты FPM и веб‑сервера.
-
-
Мониторинг:
-
полный стек Prometheus/Grafana с метриками по каждому уровню (front, app, DB, интеграции);
-
алерты по SLA‑метрикам: время ответа ключевых страниц, процент ошибок, длительность обменов с 1С и платёжными сервисами;
-
логирование в централизованную систему (ELK/ClickHouse‑логирование), чтобы быстро разбирать инциденты.
-
В таких кейсах мы вместе с заказчиком рассматриваем сервер как живую систему: важно не только «какой тип сервера», но и как именно разбиты роли по виртуалкам, как устроены бэкапы и как быстро можно восстановиться при сбое одного из уровней.
Чем в итоге помогает Bquadro
Наша задача как студии — не просто написать сайт или взять проект на системное администрирование, а сделать так, чтобы инфраструктура соответствовала бизнес-целям и могла расти вместе с проектом. Поэтому в конце такого погружения заказчик получает:
-
Понятное пояснение терминов (shared, VPS, VDS, bare metal, cloud, serverless) с привязкой к своему кейсу.
-
Таблицу сравнения вариантов размещения: ресурсы, сеть, SLA, стоимость, возможности расширения.
-
Набор целевых метрик (CPU, RAM, IOPS, latency, packet loss), по которым можно судить, «тянет ли сервер».
-
Рекомендованный стартовый вариант (часто — VDS или гибрид VDS+cloud) и план дальнейшего масштабирования.
-
Чеклист сигналов к переезду и краткий план миграции, чтобы смена сервера не превращалась в «перезапуск бизнеса».
Мы не ожидаем, что заказчик станет DevOps-инженером. Но практика показывает: чем глубже он понимает, что происходит с сервером, тем легче принимать решения о развитии продукта. И именно в этом — наша роль: перевести сложную техническую реальность CPU, NVMe, VLAN, DDoS и Prometheus на язык рисков, возможностей и роста бизнеса.